This blog is available in Japanese here: OpenSearch を使用した類似文書検索
When users need to find multiple results in your search data, such as recommendations for similar articles on a news website or recommendations for related products on an e-commerce site, you can take advantage of similar document search inside of OpenSearch. When you give OpenSearch a document as a query, similar document search retrieves contents similar to the query document.
There are two main approaches to retrieving similar documents:
- Retrieval based on the similarity of the contents to the document query
- Retrieval based on the user’s query history
This blog post focuses on the first approach and explains how to implement the approach using OpenSearch.
Similar document search in OpenSearch
1. More like this query
The traditional way to achieve similar document search is to use a More Like This (MLT) query. MLT is a search based on term frequency, which has the assumption that similar documents contain the same words. While MLT is an intuitive mechanism, it lacks the flexibility of considering context or different words with similar meanings.
MLT uses term frequency-inverse document frequency (tf-idf) to extract document features:
- Term frequency (tf) is the number of times a term appears within a document.
- Inverse document frequency (idf) is the measure of how rare the term is across all the documents.
tf-idf is the product of tf and idf. That product is used to reflect how important a word is to a document in a collection of documents. MLT analyzes an input document and selects the top k terms with the highest tf-idf to form a query. When a user enters a query, MLT uses the query to return the top similar documents.
2. k-NN
You can also use the k-nearest neighbors (k-NN) algorithm for similar document search. In k-NN, vectors represent documents. When given a query vector, k-NN returns k documents with the highest similarity. To create vectors from documents, you can use a machine learning (ML) model to position documents with similar meanings close to each other. Therefore, similar document search using k-NN allows for more advanced search than MLT because vectors can contain context and not just the same words. However, search results highly depend on the model, and it is quite difficult to understand why certain search results appears where others don’t.
OpenSearch supports k-NN search, which can use exact k-NN search or approximate k-NN for an efficient search. In order to use k-NN, you must convert the text of a field to be searched into a vector through an ML model before indexing and searching in OpenSearch. In OpenSearch 2.4, you can use the Neural Search plugin (experimental), which allows you to upload your ML models, vectorize documents and queries, and search documents using k-NN. With the Neural Search plugin, you don’t need to vectorize documents yourself when indexing and searching. The following figure shows an overview of the Neural Search plugin.
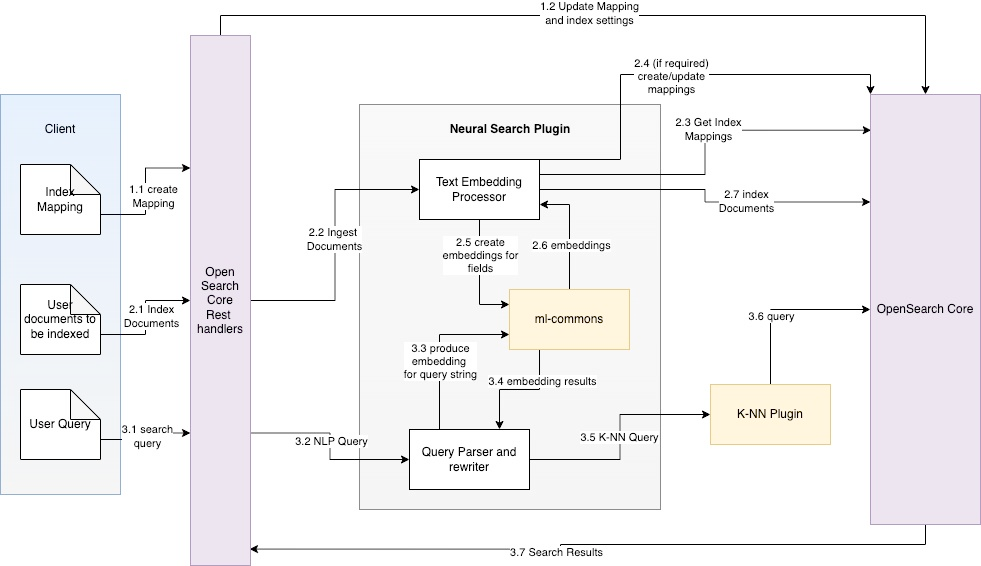
Note that Amazon OpenSearch Service, the AWS managed OpenSearch service, currently only supports versions up to 2.3, which don’t support the model-serving framework or the Neural Search plugin.
Examples of MLT and k-NN in OpenSearch
In the following examples, we use OpenSearch 2.4 to demonstrate a similar document search using both an MLT query and k-NN through the Neural Search plugin, and we compare the search results.
Building an OpenSearch environment
OpenSearch has several installation options, such as Docker, Tarball, and RPM. We use Docker for this demonstration.
Because this is just a demonstration, prepare a docker-compose.yml that uses a single node and disables security plugins:
version: "3"
services:
opensearch-node:
image: opensearchproject/opensearch:latest
container_name: opensearch-node
environment:
- discovery.type=single-node
- "DISABLE_INSTALL_DEMO_CONFIG=true"
- "DISABLE_SECURITY_PLUGIN=true"
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 9200:9200
opensearch-dashboards:
image: opensearchproject/opensearch-dashboards:latest
container_name: opensearch-dashboards
ports:
- 5601:5601
expose:
- "5601"
environment:
- "DISABLE_SECURITY_DASHBOARDS_PLUGIN=true"
- "OPENSEARCH_HOSTS=http://opensearch-node:9200"
Next, navigate to the directory of your docker-compose.yml and enter the following command to run OpenSearch and OpenSearch Dashboards:
docker compose up -d
Go to http://localhost:5601. You should be able to access OpenSearch Dashboards as shown in the following figure.
Dataset
In this example, we use The Multilingual Amazon Reviews Corpus dataset, an open-source dataset of Amazon review data. The following is a sample of the corpus, and we search for similar documents in the “review_body” field:
{
"review_id": "en_0802237",
"product_id": "product_en_0417539",
"reviewer_id": "reviewer_en_0649304",
"stars": "3",
"review_body": "I love this product so much i bought it twice! But their customer service is TERRIBLE. I received the second glassware broken and did not receive a response for one week and STILL have not heard from anyone to receive my refund. I received it on time, but am not happy at the moment.",
"review_title": "Would recommend this product, but not the seller if something goes wrong.",
"language": "en",
"product_category": "kitchen"
}
Search with MLT
You can enter a search using an MLT query with either Dev Tools in OpenSearch Dashboards or any OpenSearch client.
To start, create an index named amazon-review-index. MLT uses the statistics of the analyzed text, and you can speed up the search by storing term statistics at index time. Therefore, we set “term_vector”: “yes” for the review_body field:
PUT /amazon-review-index
{
"mappings": {
"properties": {
"review_id": { "type": "keyword" },
"product_id": { "type": "keyword" },
"reviewer_id": { "type": "keyword" },
"stars": { "type": "integer" },
"review_body": { "type": "text", "term_vector": "yes" },
"review_title": { "type": "text" },
"language": { "type": "keyword" },
"product_category": { "type": "keyword" }
}
}
}
After creating the index, we load the review data into OpenSearch. There are various ways to load data into OpenSearch, such as curl, OpenSearch language clients, or a logging tool like Data Prepper. In this example, we provide code for uploading data using opensearch-py, a Python client for OpenSearch:
import json
from opensearchpy import OpenSearch
def payload_constructor(data):
payload_string = ''
for datum in data:
action = {'index': {'_id': datum['review_id']}}
action_string = json.dumps(action) + '\n'
payload_string += action_string
this_line = json.dumps(datum) + '\n'
payload_string += this_line
return payload_string
index_name = 'amazon-review-index'
batch_size = 1000
client = OpenSearch(
hosts=[{'host': 'localhost', 'port': 9200}],
http_compress=True,
)
with open('../json/train/dataset_en_train.json') as f:
lines = f.readlines()
for start in range(0, len(lines), batch_size):
data = []
for line in lines[start:start+batch_size]:
data.append(json.loads(line))
response = client.bulk(body=payload_constructor(data), index=index_name)
After loading data, we can now perform a search with an MLT query.
There are two ways to provide a query text:
- Specify the text in the MLT query. However, search by text can increase latency since the search must perform analysis on the text.
- Specify an ID of the document that already exists in your index. This method is faster if you want to find documents similar to your indexed documents.
In the following query, we use the review data listed in the dataset section. Because sentences in this example dataset are not long, there is a possibility min_term_freq default value 2 will exclude important terms. So, we set min_term_freq to 1, the minimum term frequency for which the input document ignores.
GET amazon-review-index/_search?size=5
{
"query" : {
"more_like_this" : {
"fields" : ["review_body"],
"like": {
"_id": "en_0802237"
},
"min_term_freq": 1
}
},
"fields": ["review_body", "stars"],
"_source": false
}
Upon query completion, we receive the following results. The query text contains, “I love this product so much i bought it twice! But their customer service is TERRIBLE. I received the second glassware broken and did not receive a response for one week and STILL have not heard from anyone to receive my refund. I received it on time, but am not happy at the moment.” As you can tell from the text, a dissatisfied customer left this review. Similar document search returns results that are similar to the text query, including words such as “response”, “customer”, “service”, and “terrible”:
{
"took": 53,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 779,
"relation": "eq"
},
"max_score": 35.644646,
"hits": [
{
"_index": "amazon-review-index",
"_id": "en_0398542",
"_score": 35.644646,
"fields": {
"stars": [1],
"review_body": [
"Used it twice and the plastic clip that holds the strap snapped off. Useless now. Haven’t received a response from customer service. 5 months later, still no response. Terrible."
]
}
},
{
"_index": "amazon-review-index",
"_id": "en_0157395",
"_score": 27.64468,
"fields": {
"stars": [1],
"review_body": [
"Lost pressure in first month. Never received any response from their customer service . Total waste of money and time. Bought a different brand that works great, Do not buy this product."
]
}
},
{
"_index": "amazon-review-index",
"_id": "en_0439049",
"_score": 26.461647,
"fields": {
"stars": [1],
"review_body": [
"The product arrived damage, opened with a damaged soaking box. The seller was contacted and there was no response and no refund offered. The customer service is terrible. I do not recommend this seller."
]
}
},
{
"_index": "amazon-review-index",
"_id": "en_0021763",
"_score": 26.441845,
"fields": {
"stars": [1],
"review_body": [
"DO NOT ORDER FROM THEM!! I placed my order on February 12th and STILL have not received my item. To make matters worse I emailed the seller with my issue on March 10th and haven't so much as even gotten a response back. Terrible customer service and they just TOOK my money."
]
}
},
{
"_index": "amazon-review-index",
"_id": "en_0582638",
"_score": 26.065836,
"fields": {
"stars": [1],
"review_body": [
"Never received it! Was supposed to receive March 6. Now it’s the end of March. I’ve tried to contact the company twice with no response. Poor customer service! Don’t buy! Never received item and never got my money back! If I could give zero stars I would!!!! Amazon please intervene!"
]
}
}
]
}
}
Search with k-NN
In this example, we demonstrate similar document search with k-NN using the Neural Search plugin, following the model-serving framework and neural-search plugin documentation. For the feature extraction ML model, we use the sentence-transformer model from Hugging Face.
First, upload the ML model:
POST /_plugins/_ml/models/_upload
{
"name": "all-MiniLM-L6-v2",
"version": "1.0.0",
"description": "test model",
"model_format": "TORCH_SCRIPT",
"model_config": {
"model_type": "bert",
"embedding_dimension": 384,
"framework_type": "sentence_transformers"
},
"url": "https://github.com/opensearch-project/ml-commons/raw/2.x/ml-algorithms/src/test/resources/org/opensearch/ml/engine/algorithms/text_embedding/all-MiniLM-L6-v2_torchscript_sentence-transformer.zip?raw=true"
}
OpenSearch returns the following response after the upload:
{
"task_id": "NHBlGYUBej1j0hjelDel",
"status": "CREATED"
}
To check the status of the model upload, run the following API. Pass the task_id after /_plugins/_ml/tasks/ from the previous response:
GET /_plugins/_ml/tasks/<task_id>
If the state is COMPLETED, as shown in the following response, the model upload is complete:
{
"model_id": "NXBlGYUBej1j0hjelTc0",
"task_type": "UPLOAD_MODEL",
"function_name": "TEXT_EMBEDDING",
"state": "COMPLETED",
"worker_node": "hGSG_GzpSGePCkmCmY3cvg",
"create_time": 1671168365569,
"last_update_time": 1671168376567,
"is_async": true
}
Next, load the uploaded model in to memory. Pass the model_id from the previous response:
POST /_plugins/_ml/models/<model_id>/_load
Using the task_id in the load API response, run the _ml/tasks API. If the state is COMPLETED, the model has been successfully uploaded:
{
"model_id": "NXBlGYUBej1j0hjelTc0",
"task_type": "LOAD_MODEL",
"function_name": "TEXT_EMBEDDING",
"state": "COMPLETED",
"worker_node": "hGSG_GzpSGePCkmCmY3cvg",
"create_time": 1671238820338,
"last_update_time": 1671238820447,
"is_async": true
}
Next, create a data ingestion pipeline using the uploaded model.
- For
model_id, specify the model ID from the previous response. - For
field_map, enter the text field you want to embed in your chosen vector field. In this example, we map the text field namedreview_bodyto the vector field namedreview_embedding:
PUT _ingest/pipeline/nlp-pipeline
{
"description": "An example neural search pipeline",
"processors" : [
{
"text_embedding": {
"model_id": "<model_id>",
"field_map": {
"review_body": "review_embedding"
}
}
}
]
}
After creating the pipeline, create an index named amazon-review-index-nlp. For default_pipeline, enter the name of the pipeline you just created, and create a field named review_embedding and set the information about k-NN as follows.
PUT /amazon-review-index-nlp
{
"settings": {
"index.knn": true,
"default_pipeline": "nlp-pipeline"
},
"mappings": {
"properties": {
"review_embedding": {
"type": "knn_vector",
"dimension": 384,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "nmslib",
"parameters": {
"ef_construction": 128,
"m": 24
}
}
},
"review_id": { "type": "keyword" },
"product_id": { "type": "keyword" },
"reviewer_id": { "type": "keyword" },
"stars": { "type": "integer" },
"review_body": { "type": "text" },
"review_title": { "type": "text" },
"language": { "type": "keyword" },
"product_category": { "type": "keyword" }
}
}
}
After creating the index, we load data into the index. Data can load in the same way as in an MLT search. However, while the k-NN search contains a new field named review_embedding, you do not have to pass data to this field because the ML pipeline automatically loads data.
After uploading the data, you can search with k-NN. We use the same text as in the MLT example:
GET amazon-review-index-nlp/_search?size=5
{
"query": {
"neural": {
"review_embedding": {
"query_text": "I love this product so much i bought it twice! But their customer service is TERRIBLE. I received the second glassware broken and did not receive a response for one week and STILL have not heard from anyone to receive my refund. I received it on time, but am not happy at the moment., review_title: Would recommend this product, but not the seller if something goes wrong.",
"model_id": <model_id>,
"k": 10
}
}
},
"fields": ["review_body", "stars"],
"_source": false
}
The search results are as follows. Again, the top results are reviews that express dissatisfaction with customer service and delivery, but, unlike MLT search, the results do not include words that are common to the query. For example, the query includes the word “glassware”, but the MLT search did not return any words related to “glassware”. However, the k-NN search includes the word “glass” in the response. We can also see that words such as “ship”, which were not in the query, are also in the response.
This is just one example, but it demonstrates how a k-NN search will return results that better understand the meaning of the input text:
{
"took" : 76,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 40,
"relation" : "eq"
},
"max_score" : 0.61881816,
"hits" : [
{
"_index" : "amazon-review-index-nlp",
"_id" : "n3B3GYUBej1j0hjek1ug",
"_score" : 0.61881816,
"fields" : {
"stars" : [
1
],
"review_body" : [
"""I guess I should have trusted the other reviews, as my arrived and was broken in its box. So now I need to return it for a refund? And ship broken glass..which I'm not really comfortable with 😫"""
]
}
},
{
"_index" : "amazon-review-index-nlp",
"_id" : "aXB3GYUBej1j0hjeV1N0",
"_score" : 0.60459375,
"fields" : {
"stars" : [
1
],
"review_body" : [
"Bought this almost a week ago and it broke on me. Definitely don’t recommend getting this product. We also contacted the buyer and heard nothing back."
]
}
},
{
"_index" : "amazon-review-index-nlp",
"_id" : "e3B3GYUBej1j0hjeGE7v",
"_score" : 0.5942412,
"fields" : {
"stars" : [
1
],
"review_body" : [
"Very very very horrible customer service and product was never seen. Ordered for a christmas gift, then found out they had 8 week shipping, no sooner. When I emailed them, they responded with a very unapologetic response or solution. So yeah I never recieved this product and I would advise no one to order from them!"
]
}
},
{
"_index" : "amazon-review-index-nlp",
"_id" : "u3B2GYUBej1j0hjetkCU",
"_score" : 0.5831761,
"fields" : {
"stars" : [
1
],
"review_body" : [
"Items arrived completely smashed in the box. It was full of broken glass and amazon would not give me a refund without sending the broken pieces back. I did not feel comfortable mailing a broken box full of glass and said no, so will receive no refund."
]
}
},
{
"_index" : "amazon-review-index-nlp",
"_id" : "SHB3GYUBej1j0hje22Xg",
"_score" : 0.58303237,
"fields" : {
"stars" : [
1
],
"review_body" : [
"I bought this for a gift and when opened, the glass was broken and no usable. Very disappointed and embarrassed when my friend opened it up. this was not cheap either, so it should have been packaged better."
]
}
}
]
}
}
Wrapping it up
In this blog post, we introduced and compared two methods of similar document search: MLT and k-NN. Note that the results will vary depending on factors such as parameter tuning, synonyms, and custom dictionary settings. In order to get more suitable search results, it is also possible to combine a match query with k-NN search or MLT with k-NN search, as in the example request for neural search.
If you have any feedback, feel free to comment on [Feedback] Neural Search plugin or [Feedback] Machine Learning Model Serving Framework.
